广义SAM
文章目录
广义后缀自动机
前置知识
广义后缀自动机基于下面的知识点
请务必对上述两个知识点非常熟悉之后,再来阅读本文,特别是对于 后缀自动机 中的 后缀链接 能够有一定的理解
起源
广义后缀自动机是由刘研绎在其 2015 国家队论文《后缀自动机在字典树上的拓展》上提出的一种结构,即将后缀自动机直接建立在字典树上。
大部分可以用后缀自动机处理的字符串的问题均可扩展到 Trie 树上。——刘研绎
约定
参考 字符串约定
字符串个数为 $k$ 个,即 $S_1, S_2, S_3 … S_k$
约定字典树和广义后缀自动机的根节点为 $0$ 号节点
概述
后缀自动机 (suffix automaton, SAM) 是用于处理单个字符串的子串问题的强力工具。
而广义后缀自动机 (General Suffix Automaton) 则是将后缀自动机整合到字典树中来解决对于多个字符串的子串问题
常见的伪广义后缀自动机
- 通过用特殊符号将多个串直接连接后,再建立 SAM
- 对每个串,重复在同一个 SAM 上进行建立,每次建立前,将
last指针置零
方法 1 和方法 2 的实现方式简单,而且在面对题目时通常可以达到和广义后缀自动机一样的正确性。所以在网络上很多人会选择此类写法,例如在后缀自动机一文中最后一个应用,便使用了方法 1
但是无论方法 1 还是方法 2,其时间复杂度较为危险
构造广义后缀自动机
根据原论文的描述,应当在多个字符串上先建立字典树,然后在字典树的基础上建立广义后缀自动机。
字典树的使用
首先应对多个串创建一棵字典树,这不是什么难事,如果你已经掌握了前置知识的前提下,可以很快的建立完毕。这里为了统一上下文的代码,给出一个可能的字典树代码。
|
|
这里我们得到了一棵依赖于 next 数组建立的一棵字典树。
后缀自动机的建立
如果我们把这样一棵树直接认为是一个后缀自动机,则我们可以得到如下结论
- 对于节点
i,其len[i]和它在字典树中的深度相同 - 如果我们对字典树进行拓扑排序,我们可以得到一串根据
len不递减的序列。$BFS$ 的结果相同
而后缀自动机在建立的过程中,可以视为不断的插入 len 严格递增的值,且插值为 $1$。所以我们可以将对字典树进行拓扑排序后的结果做为一个队列,然后按照这个队列的顺序不断地插入到后缀自动机中。
由于在普通后缀自动机上,其前一个节点的 len 值为固定值,即为 last 节点的 len。但是在广义后缀自动机中,插入的队列是一个不严格递增的数列。所以对于每一个值,对于它的 last 应该是已知而且固定的,在字典树上,即为其父亲节点。
由于在字典树中,已经建立了一个近似的后缀自动机,所以只需要对整个字典树的结构进行一定的处理即可转化为广义后缀自动机。我们可以按照前面提出的队列顺序来对整个字典树上的每一个节点进行更新操作。最终我们可以得到广义后缀自动机。
对于每个点的更新操作,我们可以稍微修改一下 SAM 中的插入操作来得到。
对于整个插入的过程,需要注意的是,由于插入是按照 len 不递减的顺序插入,在进行 $clone$ 后的数据复制过程中,不可以复制其 len 小于当前 len 的数据。
算法
根据上述的逻辑,可以将整个构建过程描述为如下操作
- 将所有字符串插入到字典树中
- 从字典树的根节点开始进行 $BFS$,记录下顺序以及每个节点的父亲节点
- 将得到的 $BFS$ 序列按照顺序,对每个节点在原字典树上进行构建,注意不能将
len小于当前len的数据进行操作
对操作次数为线性的证明
由于仅处理 $BFS$ 得到的序列,可以保证字典树上所有节点仅经过一次。
对于最坏情况,考虑字典树本身节点个数最多的情况,即任意两个字符串没有相同的前缀,则节点个数为 $\sum_{i=1}^{k}|S_i|$,即所有的字符串长度之和。
而在后缀自动机的更新操作的复杂度已经在后缀自动机中证明
所以可以证明其最坏复杂度为线性
而通常伪广义后缀自动机的平均复杂度等同于广义后缀自动机的最差复杂度,面对对于大量的字符串时,伪广义后缀自动机的效率远不如标准的广义后缀自动机
实现
对插入函数进行少量必要的修改即可得到所需要的函数
|
|
- 由于整个 $BFS$ 的过程得到的顺序,其父节点始终在变化,所以并不需要保存
last指针。 - 插入操作中,
int cur = next[last][c];与正常后缀自动机的int cur = tot++;有差异,因为我们插入的节点已经在树型结构中完成了,所以只需要直接获取即可 - 在 $clone$ 后的数据拷贝中,有这样的判断
next[clone][i] = len[next[q][i]] != 0 ? next[q][i] : 0;这与正常的后缀自动机的直接赋值next[clone][i] = next[q][i];有一定差异,此次是为了避免更新了len大于当前节点的值。由于数组中len当且仅当这个值被 $BFS$ 遍历并插入到后缀自动机后才会被赋值
性质
- 广义后缀自动机与后缀自动机的结构一致,在后缀自动机上的性质绝大部分均可在广义后缀自动机上生效(后缀自动机的性质)
- 当广义后缀自动机建立后,通常字典树结构将会被破坏,即通常不可以用广义后缀自动机来解决字典树问题。当然也可以选择准备双倍的空间,将后缀自动机建立在另外一个空间上。
应用
所有字符中不同子串个数
可以根据后缀自动机的性质得到,以点 $i$ 为结束节点的子串个数等于 $len[i] - len[link[i]]$
所以可以遍历所有的节点求和得到
|
|
多个字符串间的最长公共子串
我们需要对每个节点建立一个长度为 $k$ 的数组 flag(对于本题而言,可以仅为标记数组,若需要求出此子串的个数,则需要改成计数数组)
在字典树插入字符串时,对所有节点进行计数,保存在当前字符串所在的数组
然后按照 len 递减的顺序遍历,通过后缀链接将当前节点的 flag 与其他节点的合并
遍历所有的节点,找到一个 len 最大且满足对于所有的 k,其 flag 的值均为非 $0$ 的节点,此节点的 $len$ 即为解
例题:SPOJ Longest Common Substring II
|
|
以上搬运自oi-wiki
然而oi-wiki上讲的是离线做法。为将多个模式串离线插入到$\text{Trie}$树中,然后依据$\text{Trie}$构造广义SAM.
而还有一种在线构造的做法,指不建立$\text{Trie}$,直接把给出的多个模式串依次插入到广义SAM中。下面开始搬辰星凌神仙的博客
具体来说,每次插入一个模式串之前,都把$last$设为$1$,$insert$函数在普通SAM的基础上加入特判(注意前面说的盗版写法用的是不加特判的普通$insert$)。
更新后的代码大概如下:
|
|
稍微解释一下两个特判。
特判1:在$lst$后插入一个节点$cur$满足$maxlen[cur]=maxlen[lst]+1$,而如果这个节点已经在SAM中了,那么就可以直接返回。
注意,这里返回的这个节点保存了多个模式串的状态,即将多个不同模式串的相同子串信息压缩在了这一个节点内,如果要记录${endpos}$大小的话,则需要给每个模式串都单独维护一个$siz$数组依次更新,而不能全部揉成一团
特判2的实质是处理$a[lst].son[i]\ne NULL$且$maxlen[lst]+1\ne maxlen[a[lst].son[i]]$的情况。
单串SAM的$insert$图示

图源:hihocoder
在从$last$开始往前跳parent树时,单串SAM必定存在$a[p].son[c]=NULL$的一段(在图中表现为以$u$节点结尾的最右边那一段),但扩展到多串后可能就没有这一段了,即存在$a[lst].son[i]=cur$且$maxlen[lst]+1\ne maxlen[x]$(若$maxlen[lst]+1=maxlen[cur]$的情况在特判1时就返回了)。
显然,此时没有任何节点的转移函数son或parent指针(后缀链接)指向最初新建cur的节点,同时它没有记录任何信息,因为新加入的信息全部存储在了$a[cur].nxt=x$节点上面,即从v拆出来的那个点 ,即cur是一个空节点。
可以用$minlen,maxlen$的大小推导出$cur$为空:
$cur$的parent指针会指向$v$的拆分节点$x$,而$maxlen[x]=maxlen[lst]+1$,所以$minlen[cur]=maxlen[a[cur].nxt=x]+1=maxlen[lst]+2$,又有$maxlen[cur]=maxlen[lst]+1<minlen[cur]$,而一个等价类维护的子串长度$\in[minlen,maxlen]$故$cur$为空。
从另一个角度看,节点$x$满足$a[lst].son[c]=x$且$maxlen[x]=maxlen[lst]+1$,这不正是我们需要的吗(同特判1)。所以可以返回$x$,并使用$x$作为当前模式串下一次$insert$的$lst$。
还剩下最后一个问题:前面说的这两个特判能正确地合并好等价类,但没有处理空节点$cur$。为使构造出自动机节点数与离线做法一致,我们还需进一步改进:当存在$a[lst].son[c]$时就新建$cur$节点了,直接从拆分节点开始做(或者在拆分节点之前通过特判1返回)
|
|
这里补充两张图,模拟最终版代码构造过程中特判2的运作(根为1,转移函数$trans$为黑边,后缀链接$link$为灰边):
(图一:串$aab$构造结束后的形态)
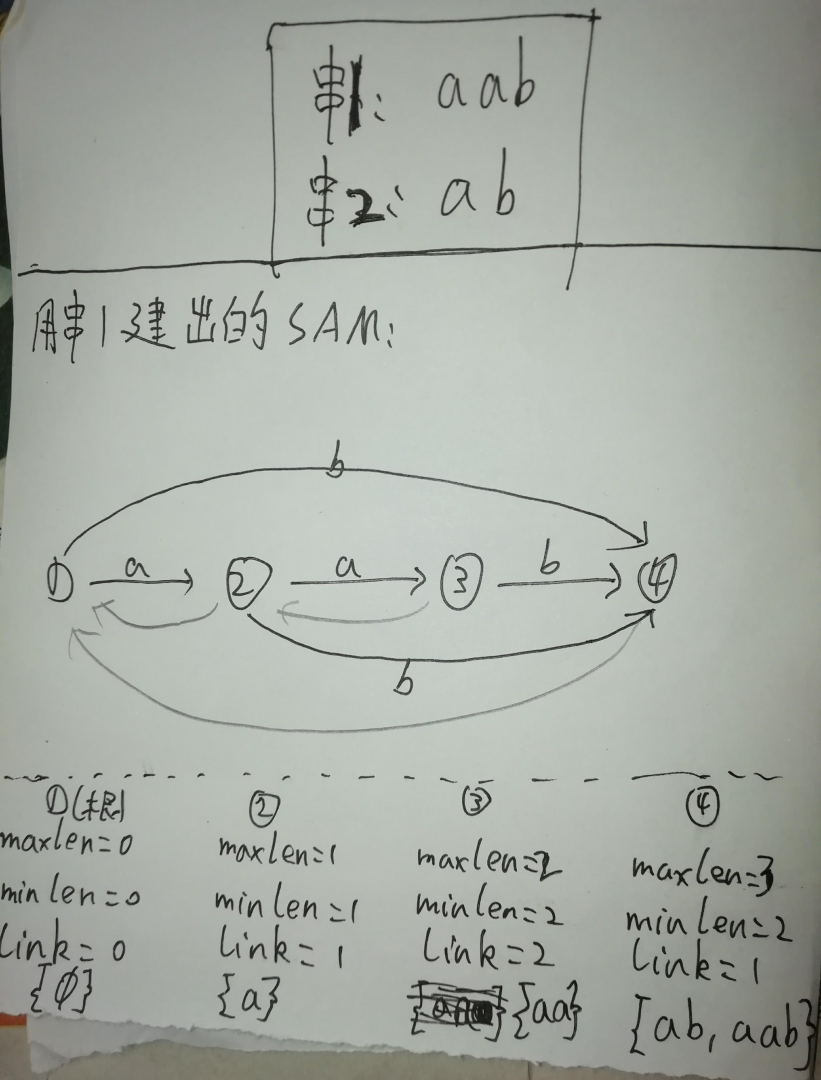
(图2:插入串$ab$中第二个字符$b$时的形态变换过程)
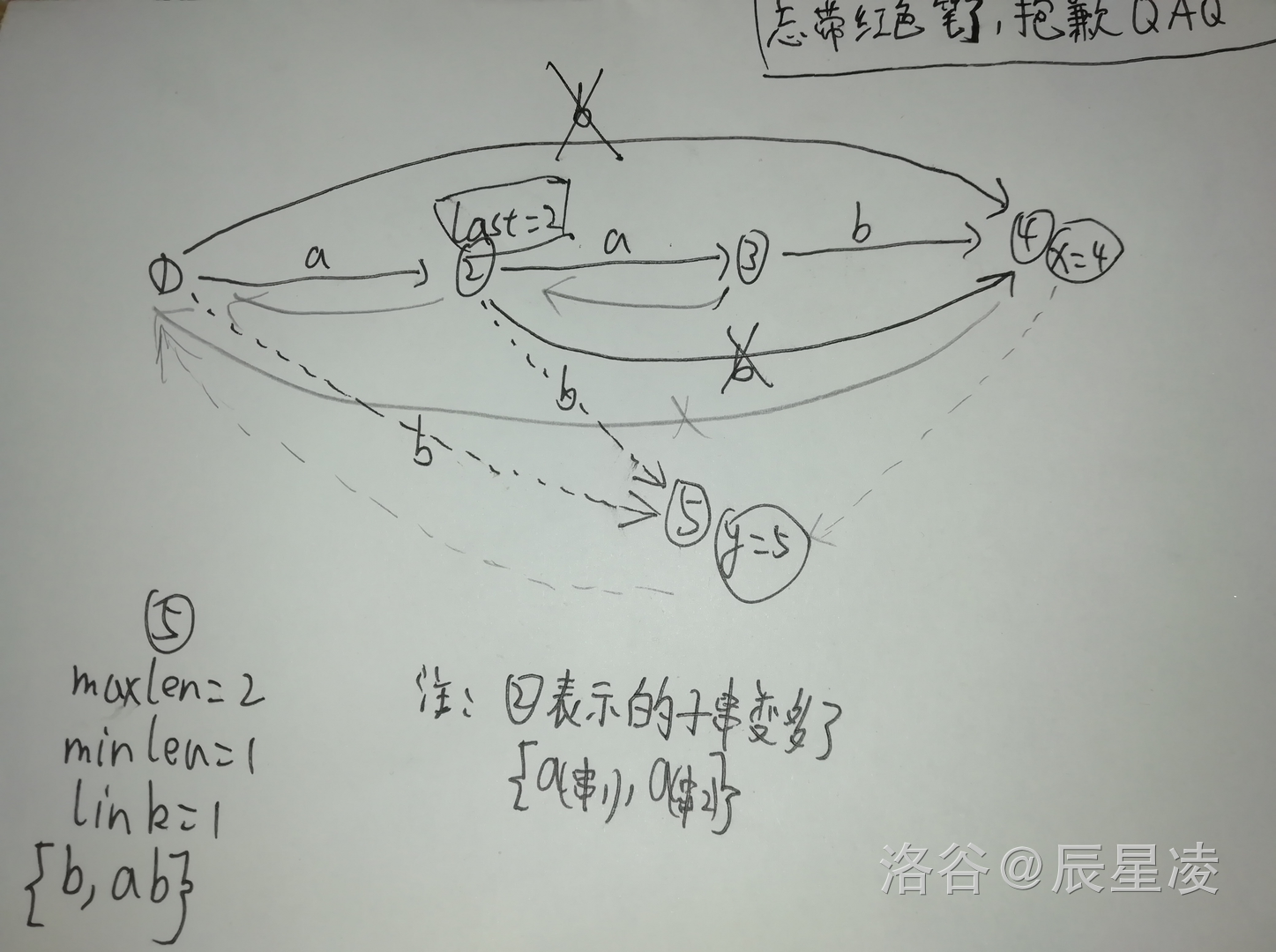
如上方黑体字所说,此时一个节点可能会存储多个字符串的信息,比如节点2:虽然表示的子串都为${a}$,但${endpos}$大小却不相同($siz_{aab}(2)=2,siz_{ab}(2)=1$)。
在线和离线的不同:在特判的作用下,在线写法会构造出一颗类$\text{Trie}$形态的SAM,其本质还是在一颗没有具象化的$\text{Trie}$树上建立了SAM。
分别维护不同串的siz
题意:求两个字符串的相同子串数量。
两个串的$|endpos|$需要分开来计算,可以开一个二维数组,用$six[x][id]$表示节点$x$在串$id$上的${endpos}$大小。
则答案为: $$ \sum siz_{i,0}\times siz_{i,1}\times(len[i]-len[link[i]]) $$
|
|
线段树合并维护siz
给定一个串$S$以及$m$个$T_i$串,有$q$次询问,每次询问$S$的子串$S[p_l\dots p_r]$在$T_{l\dots r}$中的哪个串里的出现次数最大,并输出出现次数。如果有多解输出最靠前的那一个。
先把所有字符串都插入到广义SAM中,对于每个节点开一棵下标为$[1,m]$的线段树(动态开点)线段树维护$siz$(注意插入$S$就不要在线段树上进行修改操作了)。由于$siz$的维护是统计子树和,所以插入结束后要在$parent$树上跑一下线段树合并。
查询时先在$parent$树上倍增找到包含子串$S[p_l,p_r]$的等价类状态节点,然后在该点的线段树上查询区间$[l,r]$中的最大值,顺便维护下最大值所处位置即可。
|
|
树上本质不同的路径数
题意:
给出一棵叶子节点不超过20个的无根树,每个节点上都有一个不超过10的数字,求树上本质不同的路径数(两条路径相同定义为:其路径上所有节点上的数字依次相连组成的字符串相同)。
首先有一个很麻烦的地方在于路径可以是在lca两个不同儿子节点的子树中。
而Trie树和各种自动机在"接受"字符串时都是以根为起点从上往下径直走到底。
所以要想办法把路径弄直,这里有一个不太容易想出来的的结论:
一颗无根树上任意一条路径必定可以在以某个叶节点为根时,变成一条从上到下的路径(利于广义SAM的使用)。
而题面说叶子节点不超过20个。
意味我们可以暴力枚举每一个叶节点作为根节点遍历整棵树。
将$tot_{leaf}$棵树中的所有前缀串都抽出来建立广义SAM,然后直接求本质不同的子串的个数。
这里的前缀串的定义为从根节点(无根树的某个叶子节点)到任意一个节点的路径所构造成的字符串。(其实就是$tot_{leaf}$棵Trie树合在一起跑广义SAM)。
|
|
还需要做的:例题 : SP8093 JZPGYZ - Sevenk Love Oimaster
但是我先鸽了qwq